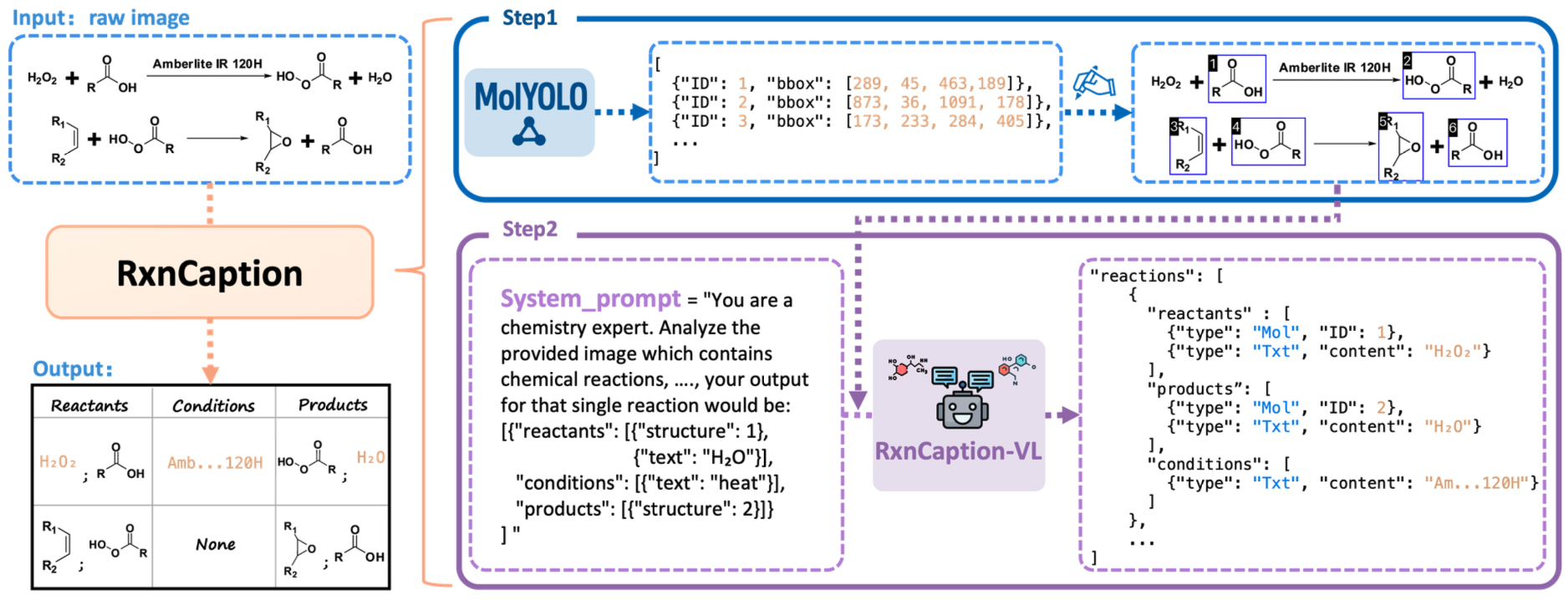
Large-scale chemical reaction datasets are crucial for AI research in chemistry. However, existing chemical reaction data often exist as images within papers, making them not machine-readable and unusable for training machine learning models. In response to this challenge, we propose the RxnCaption framework for the task of chemical Reaction Diagram Parsing (RxnDP). Our framework reformulates the traditional coordinate prediction driven parsing process into an image captioning problem, which Large Vision-Language Models (LVLMs) handle naturally.
We introduce a strategy termed "BBox and Index as Visual Prompt" (BIVP), which uses our state-of-the-art molecular detector, MolYOLO, to pre-draw molecular bounding boxes and indices directly onto the input image. This turns the downstream parsing into a natural-language description problem. Extensive experiments show that the BIVP strategy significantly improves structural extraction quality while simplifying model design.
We further construct the U-RxnDiagram-15k dataset, an order of magnitude larger than prior real-world literature benchmarks, with a balanced test subset across four layout archetypes. Experiments demonstrate that RxnCaption-VL achieves state-of-the-art performance on multiple metrics.
We believe our method, dataset, and models will advance structured information extraction from chemical literature and catalyze broader AI applications in chemistry. We will release data, models, and code on GitHub.
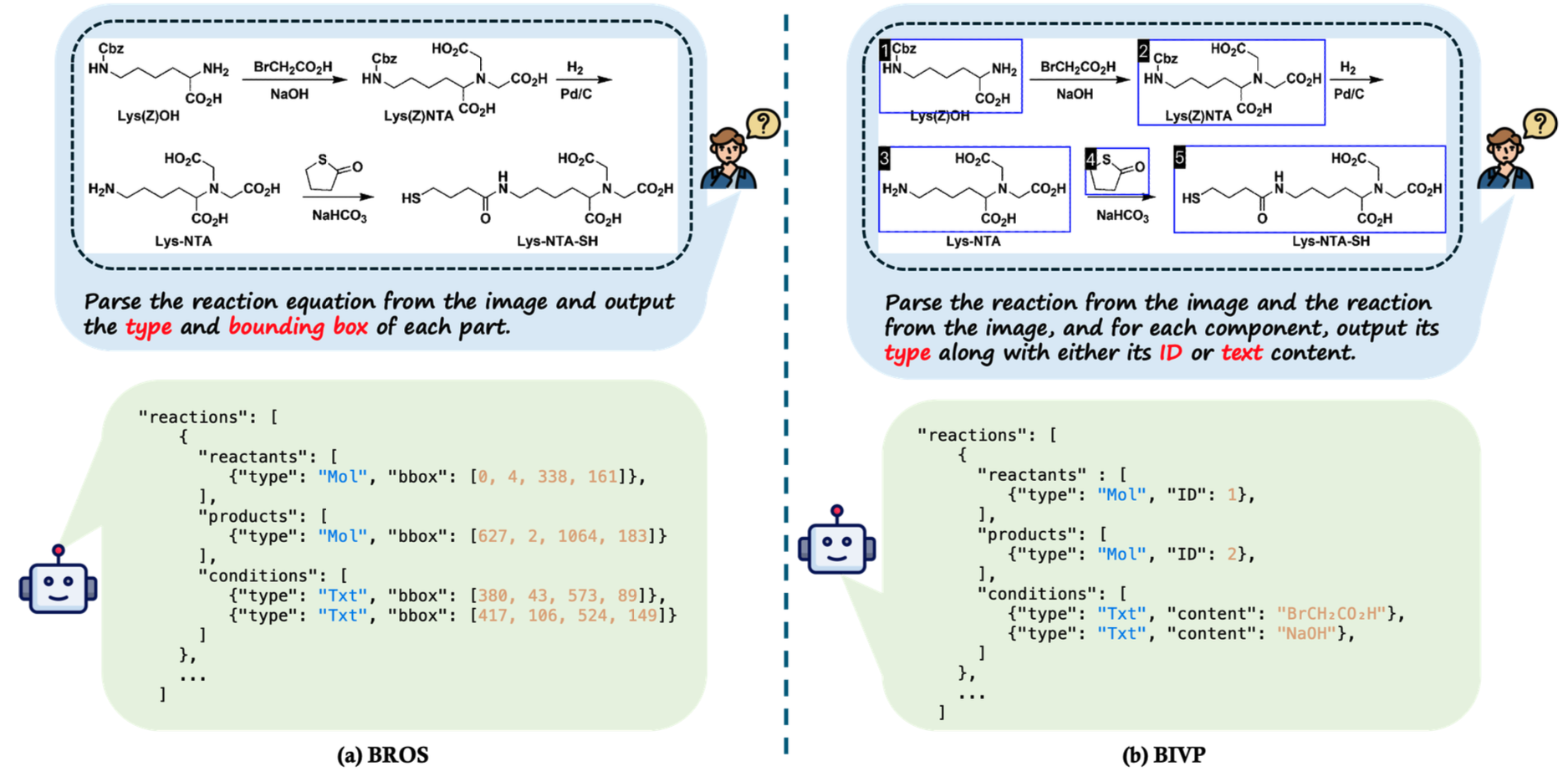
Unlike the traditional "Bbox and Role in One Step" (BROS) strategy which forces LVLMs to perform coordinate prediction, our BIVP strategy uses visual indices to transform parsing into a Natural Language Description task, perfectly aligning with inherent LVLM capabilities.
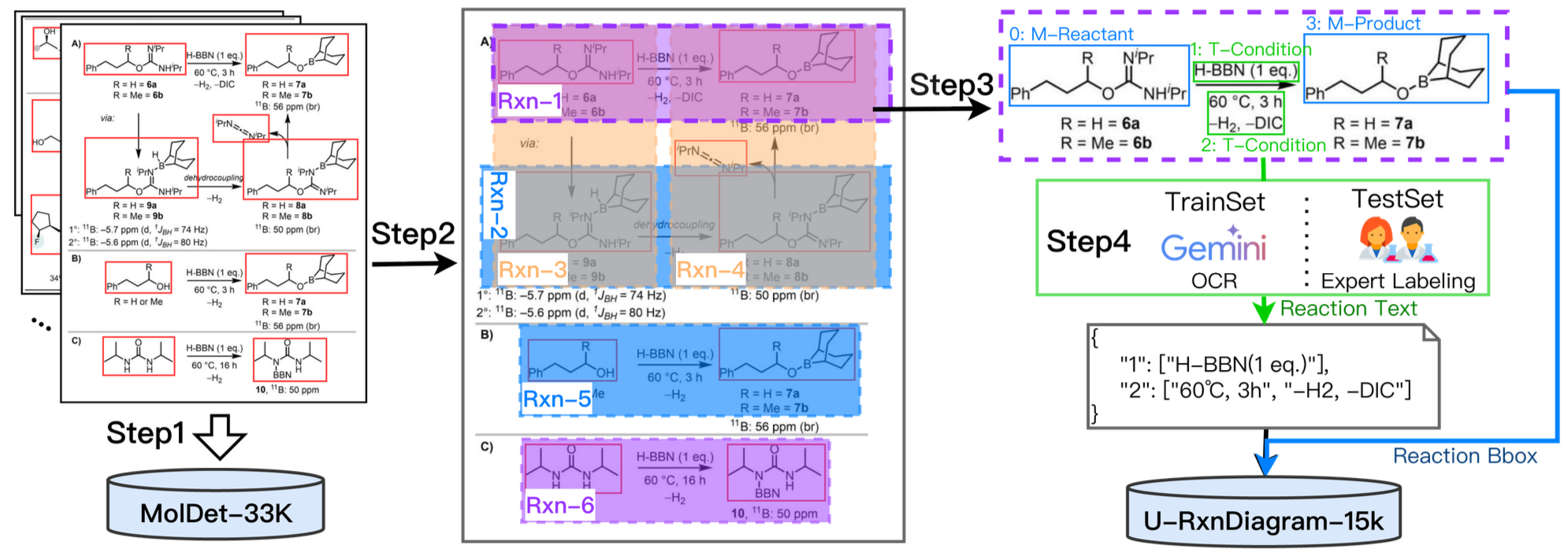
Collected from real-world papers, the U-RxnDiagram-15k dataset contains 15k images, exceeding the RxnScribe dataset by an order of magnitude. We specifically designed a balanced test set to address layout biases across single, multi, tree, and cyclic reactions, creating a rigorously more challenging benchmark for model evaluation.
| Model | Strategy | RxnScribe-test | U-RxnDiagram-15k-test | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hybrid Match | Soft Match | Hybrid Match | Soft Match | ||||||||||
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| Trained Model | |||||||||||||
| RxnCaption-VL | BIVP | 71.6 | 72.7 | 72.2 | 85.3 | 87.1 | 86.2 | 60.3 | 59.3 | 59.8 | 71.3 | 69.4 | 70.4 |
| BROS | 69.6 | 68.9 | 69.2 | 76.2 | 76.2 | 76.2 | 57.0 | 57.5 | 57.2 | 66.4 | 67.4 | 66.9 | |
| RxnScribe_w/15k | BROS | 72.4 | 69.1 | 70.7 | 84.1 | 81.7 | 82.8 | 61.2 | 38.7 | 47.4 | 72.1 | 44.7 | 55.2 |
| RxnScribe_official | BROS | 72.3 | 66.2 | 69.1 | 83.8 | 76.5 | 80.0 | 47.4 | 27.6 | 34.9 | 62.1 | 36.4 | 45.9 |
| RxnIM | BROS | 71.0 | 70.1 | 70.5 | 79.2 | 74.7 | 76.9 | 48.8 | 30.3 | 37.4 | 52.9 | 32.8 | 40.5 |
| Open-source Model | |||||||||||||
| Intern-VL3-78B | BIVP | 33.8 | 44.1 | 38.3 | 45.8 | 59.8 | 51.9 | 13.0 | 15.5 | 14.1 | 26.6 | 32.0 | 29.0 |
| BROS | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.1 | 0.1 | 0.1 | 0.3 | 0.2 | 0.3 | |
| Qwen2.5-VL-7B | BIVP | 6.0 | 4.1 | 4.9 | 55.8 | 36.0 | 43.8 | 2.9 | 0.9 | 1.4 | 33.0 | 10.3 | 15.6 |
| BROS | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| Qwen2.5-VL-72B | BIVP | 51.9 | 48.5 | 50.1 | 70.0 | 66.3 | 68.1 | 30.9 | 23.8 | 26.9 | 52.8 | 41.6 | 46.5 |
| BROS | 2.0 | 1.4 | 1.6 | 15.2 | 11.2 | 12.9 | 0.3 | 0.3 | 0.3 | 4.2 | 1.9 | 2.6 | |
| Closed-source Model | |||||||||||||
| Gemini-2.5-Pro | BIVP | 44.7 | 56.1 | 49.8 | 67.9 | 86.5 | 76.1 | 38.9 | 42.1 | 40.4 | 64.2 | 69.2 | 66.6 |
| BROS | 0.0 | 0.0 | 0.0 | 25.2 | 23.5 | 24.3 | 0.3 | 0.2 | 0.3 | 8.9 | 4.6 | 6.0 | |
| GPT4o-2024-11-20 | BIVP | 26.8 | 33.2 | 29.6 | 49.1 | 58.0 | 53.2 | 16.1 | 16.6 | 16.3 | 32.6 | 32.7 | 32.6 |
| BROS | 0.3 | 0.3 | 0.3 | 2.0 | 1.8 | 1.9 | 0.0 | 0.0 | 0.0 | 0.4 | 0.3 | 0.3 | |
| Qwen-VL-Max | BIVP | 50.0 | 46.9 | 48.4 | 71.1 | 67.6 | 69.3 | 34.0 | 29.0 | 31.3 | 55.3 | 48.4 | 51.6 |
| BROS | 0.3 | 0.3 | 0.3 | 7.2 | 5.9 | 6.5 | 0.2 | 0.1 | 0.2 | 3.2 | 2.6 | 2.8 | |
RxnCaption-VL achieves SOTA performance on both RxnScribe-test and U-RxnDiagram-15k-test benchmarks, consistently outperforming leading open-source and proprietary models. BIVP demonstrates a comprehensive advantage, yielding a remarkable 10.0 point surge in Soft-F1 accuracy compared to the BROS baseline.
@article{song2025rxncaption,
title={RxnCaption: Reformulating Reaction Diagram Parsing as Visual Prompt Guided Captioning},
author={Song, Jiahe and Wang, Chuang and Jiang, Bowen and Wang, Yinfan and Zheng, Hao and Wei, Xingjian and Liu, Chengjin and Nie, Rui and Gao, Junyuan and Sun, Jiaxing and others},
journal={arXiv preprint arXiv:2511.02384},
year={2025}
}